Java 기본 - 예외, 예외 처리
자바의 에외의 기본적인 개념들을 정리
Contents
(본 글은 기록 목적이 비교적 강하므로 설명이 불친절하고 체계적이지 않고, 자세하지 않을 수 있습니다.)
(본 글은 필자의 네이버 블로그 에서 가져왔습니다. 이는, 정리한 글들을 한 곳에 모아 개인적으로 보기 편하기 위함입니다. 따라서 기본적으로 해당 블로그에 있는 글과 본 글은 본질적으로는 같은 글입니다. )
개요
컴퓨터에서는 언제든지 오류가 발생할 가능성이 있다. 없으면 좋겠지만, 완전히 없애는 것은 불가능에 가깝다.
당연히 자바에서도 오류가 발생한다. 이를 error라고 표현한다.
자바에서 말하는 error는 java.lang.Error를 말한다. 이는 JVM이실행에 문제가 있을 때 발생시킨다. OutOfMemoryError등이 여기에 속한다. OutOfMemoryException은 말 그대로 메모리가 꽉 찾을 때 발생한다.
보다시피 Error들은 발생한 시점에서 개발자가 할 수 있는 것이 없다. 그냥 JVM이 종료되어버린다. 애초에 저 Error가 안뜨도록 노력하는 것 밖에 없다.
하지만 예외(Exception)는 Error와 달리 개발자가 처리할 수 있다. 기본적으로 예외 또한 발생하면 프로그램이 종료되는 것은 같지만, 예외 처리를 통해 실행을 유지하게 할 수 있다.
예외
예외 처리에 대해 알아보기 전에 예외에 대해 알아보자
자바는 예외가 발생하면 해당 예외에 대한 정보를 담은 클래스를 던져준다. 이 클래스가 java.lang.Exception을 상속한 클래스들이다. 이 예외 클래스들은 크게 나누면 두가지로 나뉜다.
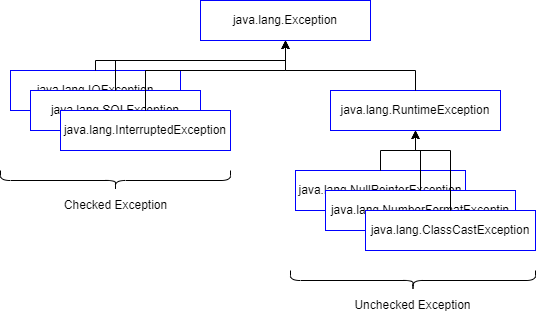 Exception의 종류
Exception의 종류
위 그림에서 좌측의 클래스들이 Checked Exception(일반 예외) 클래스들이다. 일반 예외, 체크 예외라고도 불린다. 체크 예외는 반드시 예외 처리 코드를 추가할 것을 요구한다.
만약 체크 예외가 발생할 가능성이 있는 곳에 예외 처리 코드를 추가하지 않으면 컴파일 에러가 발생한다.
컴파일러는 컴파일 시에 사용되는 메소드에서 Exception을 throw 하는지 체크한 후, 그것이 Checked Exception이라면 예외 처리를 요구한다.
IDE를 사용할 때, 위의 Checked Exception이 발생하는 코드를 작성하면 경고 표시와 함께 예외 처리 구문을 추가해주는 버튼이 뜨는 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public class Example {
public static void main(String[] args) {
Thread thread = new Thread() {
@Override
public void run() {
try {
Thread.sleep(5000); // 5초 동안 sleep
} catch (InterruptedException e) {
System.out.println(e.getMessage());
}
}
};
thread.start();
thread.interrupt(); // 스레드 인터럽트
}
}
InterruptedException은 Checked Exception이다. 따라서 해당 예외를 throw하는 메소드가 실행되었다면, 반드시 try-catch문을 사용해 처리하거나 throws를 통해 호출한 측으로 떠넘길 것을 요구한다.
오른쪽의 RuntimeException을 상속받은 클래스들이 UnChecked Exception(실행 예외) 클래스들이다. 컴파일러가 메소드가 throw 하는 예외들을 검사할 때, 던져지는 예외가 RuntimeException의 하위 객체라면 경고를 발생시키지 않는다. 즉, 컴파일 단계에서 처리를 강요하지 않는 것이다.
따라서 이러한 예외의 처리는 온전히 개발자의 몫이다. 만약 빠뜨려서 실행 중 실행 예외가 발생하면 프로그램은 여지없이 종료될 것이다.
실행 예외의 대표적인 예시는 아래와 같다.
1
2
3
4
5
6
public class Test {
public static void main(String[] args) {
String str = null;
System.out.println(str.length());
}
}
위의 코드가 실행되면 NullPointerException이 발생되고 프로그램이 비정상 종료된다. str이 인스턴스가 아닌 null 값을 가지고 있을 때, str에 . 연산자를 통해 접근하였기 때문이다. 이 예외의 발생 자체를 막기 위해서는 null 체크를 확실하게 해주는 것이 좋다.
그 외에도 ArrayIndexOutOfBoundsException이 있다. 이는 이름에서도 유추가능하듯이 배열의 범위를 초과하여 사용할 때 발생한다.
1
2
int[] arr = new int[3];
arr[4] = 10; //ArrayIndexOutOfBoundsException
이 또한 접근하기 전에 length등을 통해 미리 길이를 확인하면 예외 발생을 막을 수 있다.
위의 예시들은 모두 제한적으로나마 if문 등을 통해 사전에 방지할 수 있다. 그리고 가능하면 그렇게 하는게 빠르고 좋다. 예외 처리 코드는 분기문보다 오버헤드가 심하기 때문이다.
하지만 사전에 방지하기 어려운 예외들도 존재한다. 아래 예시를 보자.
1
2
String str = "a1b2c3";
int stoi = Integer.parseInt(str); //NumberFormatException 발생
Integer 클래스의 parseInt(String)은 문자열을 숫자로 바꾼 뒤 반환하는 메소드이다.
이 메소드는 매개 변수로 받은 문자열이 숫자로 바꿀 수 있다면 결과값을 리턴하고, 바꿀 수 없다면 NumberFormatException을 throw한다. 메소드 선언에도 throws NumberFormatException이 붙어 있다.
변환하고자 하는 문자열은 사용자의 입력이나 코드 진행에 따라 바뀔 수 있으므로 사전에 체크하기가 어렵다. 따라서 이때는 예외 처리 코드를 활용하는 것이 좋다.
예외 처리
예외 처리는 말 그대로 예외를 처리해주어서 프로그램이 예기치 못하게 종료되는 것을 막기 위해 한다. 예외 처리를 할때에는 try-catch-finally 블록을 사용한다. 아래와 같은 구조를 가진다.
1
2
3
4
5
6
7
try {
//예외가 발생할 가능성이 있는 코드
} catch(예외클래스 e) {
//예외 발생 시 실행할 코드
} finally {
//예외 여부에 상관 없이 실행되는 코드
}
try 내부의 코드에서 예외가 발생할 경우, 뒤의 코드는 실행되지 않고 바로 catch 블록으로 이동한다. catch 블록의 실행이 끝나면 finally 블록이 실행된다.
만약 try 내부의 코드가 정상적으로 실행되면 catch 블록을 건너뛰고 finally 블록으로 이동한다. 이때 finally 블록은 생략 가능하다.
기본적으로 예외가 발생할 수 있는 코드를 try 문으로 감싼 뒤 예외가 발생할 경우 실행할 부분을 catch 블록에 작성한다.
catch 블록에서는 주로 사용자나 디버그 콘솔에 에러 정보를 출력한 뒤 종료하거나, 오류가 발생했을 때 복구할 수 있는 코드를 작성한다. (반복문을 활용하여 일정 시간 대기 후 다시 시도하는 등등)
finally 블록에서는 주로 사용한 리소스를 반납하는 등의 예외에 상관없이 수행해야하는 정리 코드를 작성한다.
사용 예시를 간단하게 살펴보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import java.util.Scanner;
public class Test {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.next();
sc.close();
int inputValue;
try {
inputValue = Integer.parseInt(str);
System.out.println(inputValue);
} catch(NumberFormatException e) {
System.out.println("Wrong Input");
System.exit(2);
}
System.out.println("Success!");
}
}
위와 같이 사용자의 입력을 받아서 처리할 때에는 Runtime Exception이 발생할 확률이 매우 높다. 위에서는 사용자가 숫자로 변환할 수 없는 값을 입력하면 Wrong Input을 출력한 후 프로그램을 종료하고, 그렇지 않으면 입력한 값을 출력한 후 Success!를 띄운다.
아래와 같이 제대로 된 값을 입력할 때까지 반복할 수도 있다.
잘못된 값을 입력했다는 이유로 프로그램을 껐다가 다시 켜야하는 것은 불편하므로 GUI 프로그램등에서는 아래와 같은 방식이 더 적절할 것이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class Test {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);;
while(true) {
try {
String str = sc.next();
int inputValue = Integer.parseInt(str);
System.out.println(inputValue);
break;
} catch(NumberFormatException e) {
System.out.println("Wrong Input\n"
+ "Try Again");
} finally {
sc.nextLine(); //for flush
}
}
sc.close();
System.out.println("Success!");
}
}
예외가 발생하면 예외가 발생한 아래 라인은 실행되지 않고 바로 catch 문으로 이동하므로 break; 가 실행되지 않아 루프를 돌게 된다. 예외가 발생하지 않으면 break; 를 통해 while문을 빠져나와 프로그램을 종료한다.
다중 catch
코드에서 예외가 한 종류만 던져지란 법은 없다. 한 코드 내에서 여러 종류의 예외가 던져질 수 있다. 이를 처리하기 위해 catch문을 여러개 작성할 수 있다.
1
2
3
4
5
6
7
8
9
try {
//예외가 발생할 가능성이 있는 코드
} catch(예외클래스1 e) {
//예외 발생 시 실행할 코드
} catch(예외클래스2 e) {
//예외 발생 시 실행할 코드
} finally {
//예외 여부에 상관 없이 실행되는 코드
}
예외 클래스가 던져지면 위에서 부터 차례대로 해당 예외에 맞는 catch 블록을 찾은 후, 해당 예외에 맞는 타입을 받는 catch 블록이 실행된다.
1
2
3
4
5
6
7
8
9
10
11
Scanner sc = new Scanner(System.in);
int[] arr = new int[3];
try {
String str = sc.next();
int inputValue = Integer.parseInt(str);
arr[5] = inputValue;
} catch(NumberFormatException e) {
System.out.println("Wrong Input");
} catch(ArrayIndexOutOfBoundsException e) {
System.out.println("Array Error");
}
위의 코드에서는 사용자가 숫자로 변환되지 않는 문자열을 입력하면 parseInt에서 예외가 발생해 첫번째 catch 블록이 실행된다.
만약 숫자로 변환되는 문자열을 입력하면 아래에 있는 arr[5]에서 예외가 발생해 두번째 catch 블록이 실행된다. 이렇게 catch 블록은 한번에 하나만 실행된다. 예외가 발생한 시점에서 바로 catch 블록으로 이동하기 때문이다.
이 다중 catch를 사용할 때에는 주의해야할 점이 있다. 바로 catch문을 작성하는 순서이다. 상위 예외 클래스가 하위 예외 클래스보다 아래에 위치해야 한다.
예외가 발생하면 위에서 부터 차례로 해당 예외 클래스를 받는 catch 블록을 찾는다. 이때, 맞는 것을 찾으면 그 catch 블록에 해당 예외 클래스를 넘기고 실행한다.
상속과 다형성에서 설명했다시피 하위 객체는 상위 객체 변수에 들어갈 수 있다. 따라서 해당 예외 클래스의 상위 클래스를 받는 catch 블록이 먼저 발견되면, 아래에 해당 예외 클래스를 받는 catch블록이 있더라도 위에 있는 catch가 실행되게 된다. 이것은 잘못된 코드이다. 아래 예시로 보자.
1
2
3
4
5
6
7
8
try {
int[] arr = new int[5];
arr[100] = 99;
} catch(Exception e) {
System.out.println("Exception");
} catch(ArrayIndexOutOfBoundsException e) {
System.out.println("Out of Range");
}
위의 코드를 작성하면 IDE 등에서 Unreachable catch block ...... 라며 에러를 띄울 것이다. 말 그대로 해당 catch 블록에 닿을 수 없다는 뜻이다. 상위 객체를 받는 블록이 먼저 있기 때문이다. 위의 코드가 정상적으로 실행되려면 두 블록의 위치를 바꾸거나 닿지 못하는 블록을 지워야 한다.
아래처럼 하나의 catch 블록에서 여러개의 예외를 받을 수도 있다. 여러개의 예외에 대해 같은 처리를 하고 싶을 때 유용하다.
1
2
3
4
5
try {
//여러 예외가 발생 가능한 코드
} catch(예외1 | 예외2 | ,,,,,, | 예외n e) {
//여러 예외에 대한 통일된 처리과정
}
| 단순히 처리할 예외들을 “ | ” 기호로 이어주면 된다. |
사실, Exception으로 받으면 모든 예외에 대해 같은 처리를 할 수 있지만, 그러면 예상치 못한 예외가 생겼을 경우 알아내기 어려우므로 예상되는 예외 여러개를 위와 같이 쓰는 것이 좋다.
try문을 이용한 리소스 처리.
입출력 스트림이나 소켓 같은 리소스는 사용 후 닫지 않으면 예상치 못한 문제가 발생할 가능성이 크다. 따라서 기본적으로 사용이 끝난 리소스는 close() 호출 등을 통해 닫아 주어야 한다.
try-with-resources를 사용하면 사용한 리소스를 명시적으로 close하지 않아도 자동으로 close 해준다. 예시로 보는 것이 더 쉬우므로 예시로 살펴보자. (Stream이나 입출력에 관해서는 나중에 다룬다.)
1
2
3
4
5
6
7
8
9
10
11
FileInputStream fs = null;
try {
fs = new FileInputStream("file.txt");
......
} catch(IOException e) {
......
} finally {
if(fs != null) {
try { fs.close(); }catch(IOException e) {}
}
}
원래는 리소스를 안전하게 닫기 위해서는 위와 같이 복잡하게 써야 했다. FileInputSystem과 같은 리소스를 사용하므로 반드시 IOException을 처리해야 하고, 이후 리소스를 닫는 close() 호출또한 IOException을 처리해야 해서 저렇게 finally문에서도 try-catch를 사용해야 했다. 하지만 try-with-resources를 사용하면 아래와 같이 간결하게 변한다.
1
2
3
4
5
6
try(FileInputStream fs = new FilseInputStream("file.txt")) {
......
} catch(IOException e) {
......
}
try 블록이 정상적으로 실행되면 close()를 자동으로 호출한다. 만약 try 블록에서 예외가 발생하면 close()를 자동으로 호출한 뒤, catch 블록을 실행한다. 따로 명시적으로 리소스를 닫을 걱정을 하지 않아도 되는 것이다.
여러개의 리소스를 한번에 사용할 경우에는 아래와 같이 쓴다.
1
2
3
4
5
6
7
8
try(
FileInputStream fs = new FileInputStream("input.txt");
FileOutputStream os = new FileOutputStream("output.txt")
){
......
} catch(IOException e) {
......
}
try-with-resources에서 사용되는 리소스 객체는 AutoCloseable 인터페이스를 구현해야 한다.
AutoCloseable 인터페이스는 void close() 메소드 하나만을 가진 인터페이스로, 이 인터페이스가 구현되어 있어야 try문이 자동으로 이 close()를 호출해준다.
자체적인 리소스 객체를 만들었는데, 이 try-with-resources를 사용하고 싶다면 AutoCloseable 인터페이스를 구현하면 된다는 것이다.
예외 떠넘기기
간단한 구조의 프로그램이라면, 메소드 내부에서 예외가 발생하면 보통은 그 메소드 내에서 try-catch문을 사용해서 처리하는 경우가 많지만, throws를 통해서 호출한 곳에서 처리하라고 떠넘길 수도 있다.
기본 구조는 아래와 같다.
1
2
3
public void method() throws SQLException, NullPointerException, ...... {
......
}
메소드 선언과 몸체 사이에 throws 키워드를 넣고, 그 뒤에 콤마를 구분자로 하여 떠넘길 예외 클래스들을 쓰면된다.
이렇게 throws가 있는 메소드는 예외가 발생할 수 있다는 뜻이므로 try 블록 내에서 사용될 것을 요구한다. 만약 해당 메소드 내에서 처리하지 않고 다시 떠넘기고 싶다면 아래 처럼 다시 throws를 통해 떠넘길 수 있다. (해당 메소드가 throws하는 예외가 RuntimeException을 상속받은 실행 예외라면 try 블록 내에서 사용하거나, 상위 메소드로 throws할 것을 강제하지 않는다.)
1
2
3
4
public int stoi(String str) throws NumberFormatException {
int temp = Integer.parseInt(str);
return temp;
}
1
2
3
4
5
public void method() throws NumberFormatException {
String str = "aaaa3333";
int result = stoi(str);
System.out.println("Result : " + result);
}
저렇게 throws로 다시 떠넘기는 것은 아무 제한 없이 계속 중첩될 수 있다. 그렇게 떠넘기진 예외는 호출한 메소드로 계속 떠넘겨지다가 main까지 도달한다.
이 main에서도 throws를 통해 떠넘기면 최종적으로 자바 가상 머신이 처리하게 된다. 자바 가상 머신까지 예외가 도달하게 되면 콘솔에 예외 내용을 출력 후 종료하는 절차를 밟게 된다.
그렇다면 이렇게 예외를 떠넘기는 이유는 무엇일까? 그 이유는 여러가지가 있다. 먼저, 예외 처리 코드의 중복을 최소화할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public void addUser(User user) {
......
try {
//SQLException이 발생할만한 코드
} catch(SQLException e) {
System.out.println(/*에러난 SQL문 출력*/);
}
......
}
public void delUser(User user) {
......
try {
//SQLException이 발생할만한 코드
} catch(SQLException e) {
System.out.println(/*에러난 SQL문 출력*/);
}
......
}
위의 두 메소드는 서로 다른 역할을 하지만 같은 예외가 발생할 수 있다. 또한 처리도 동일하다. 저렇게 각 메소드에서 각각 처리하면 같은 처리 코드를 여러곳에 작성해야 한다. 이렇게 되면 코드 중복이 많이 생겨 수정과 관리에 지장이 생긴다.
1
2
3
4
5
6
7
public void addUser(User user) throws SQLException {
......
}
public void delUser(User user) throws SQLException {
......
}
1
2
3
4
5
6
7
8
try {
......
addUser(user);
......
delUser(user);
} catch(SQLException e) {
System.out.println(/*에러난 SQL문 출력*/);
}
throws를 사용해 떠넘기면 위와 같이 호출한 측에서 일괄적으로 처리할 수 있어서 코드 중복이 줄어든다.
또한, 예외 처리의 책임을 분리하여 객체 지향을 더 잘 지킬 수 있다. 각 메소드는 본연의 기능에만 집중하고 예외 처리는 호출하는 측으로 떠넘기는 것이다.
예외의 처리를 상황에 따라 유연하게 바꿀 수 있다는 점도 메리트가 있다.
메소드 내에서 처리하게 되면, 호출하는 메소드에서는 그 처리 방식이 마음에 들지 않더라도 따를 수 밖에 없다. 상황에 따라 다른 방식으로 처리하고 싶을 수도 있을 텐데 말이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
......
int maxRetry = 5;
while(maxRetry > 0) {
maxRetry--;
try {
......
addUser(user);
......
delUser(user);
......
return;
} catch(SQLException e) {
System.out.println("SQLExceptoin. retry......);
Thread.sleep(50);
}
}
throw new MaxRetryFailedException();
......
위의 메소드는 실행 중 SQLException이 발생하면 콘솔에 표시하고 잠시 대기후 다시 시도한다. 시도 횟수가 최대 횟수를 초과하게 되면 새로운 예외를 던지고 메소드를 종료한다.
위와 같이 호출하는 측에 따라 서로 다른 예외 처리 정책을 사용하고 싶을 수도 있다. 그럴 때, throws를 통해 호출하는 측에 예외 처리를 전가하면 유연하게 대응할 수 있다.
꼭 모든 예외를 위에 전가해야 하는 것은 아니다. 해당 메소드에서 처리해도 되는 것은 처리하고 더이상 처리하기 어려울 경우에는 위에 떠넘기는 것도 가능하다.
위에서 설명한 예시가 훌륭한 예시이다. delUser나 addUser에서 발생한 SQLException은 해당 메소드에서 처리하여 재시도를 통해 복구를 시도한다.
하지만 재시도에도 불구하고 처리하지 못하면 새로운 예외를 만들어 던지고 메소드를 종료한다.
위의 메소드가 throws를 통해 해당 예외를 위에 전가했다면, 상위 메소드는 해당 예외가 발생했을 경우 재시도에도 불구하고 예외 처리에 실패했음을 알게되고, 그에 따른 적절한 처리를 시도할 수 있을 것이다. 물론 상위 메소드에서도 실패하면 다시 상위로 떠넘기면 된다.
만약 한꺼번에 모든 예외를 상위 메소드로 전가해버렸다면 재시도를 통해 복구하고 실패할 경우 다른 방법을 시도하는 모든 코드가 상위 메소드에 작성되어야 할 것이다. 그렇게 되면 너무 복잡해지게 되고 오류가 생길 가능성도 높아질 것이다.
사용자 정의 예외
자바의 표준API나 프레임워크에 포함된 예외 클래스만으로는 부족할 수 있다.
개발을 하다보면 일반적인 상황에서는 예외가 아니지만 프로젝트에서는 예외로 처리해야 할 경우가 있다. 예를 들면, 중복된 값이 들어가면 안되는 곳에 중복된 값을 넣으려 할때, 상정한 범위 밖의 값이 들어왔을 때 등의 경우가 있다.
이러한 예외는 기존 예외 클래스로는 명확하게 전달되지 않는다. 물론 if문 등을 통해 처리할 수도 있겠지만, 위에서 설명한 throws의 장점들과 가독성을 위해 예외 클래스를 사용하는 것이 좋다.
사용자 정의 예외 클래스는 아래와 같이 Exception이나 RuntimeException의 하위 클래스를 작성하면 된다.
1
2
3
public class 예외클래스명 extends [Exception or RuntimeException] {
//생성자들
}
외클래스명은 알아보기 쉽게 ~Exception으로 끝나는 것이 좋다.
Excecption을 상속받으면 체크 예외가 되어 컴파일러가 처리를 강요하게 만들 수 있다. 반드시 처리되어야 할 예외를 작성할 때 사용한다.
RuntimeException을 상속받으면 컴파일러가 처리를 요구하지 않는다. 즉, try-catch문이나 throws를 사용할 것을 강요하지 않는다.
처리가 필요할때와 처리하지 않고 무시해야할 때가 공존할 때 사용하는 것이 좋다.
예외 클래스에서 작성하는 생성자들은 기본적으로 아래와 같다.
1
2
3
4
5
6
public class ExampleException extends [Exception or RuntimeException] {
public ExampleException() {}
public ExampleException(String msg) { super(msg); }
public ExampleException(Throwable cause) { super(cause); }
......
}
기본생성자와, String 을 매개변수로 받는 생성자가 있다.
String을 매개변수로 받는 생성자는 메시지를 받아서 상위 클래스의 생성자를 통해 메시지를 전달한다.
이를 통해 전달된 메시지는 getMessage() 메소드를 통해 사용할 수 있다. 예외를 발생시킬 때, 메시지를 통해 상세한 정보를 전달하고 싶을 때 이 생성자를 사용하면 된다.
이 외에도 Throwable 구현 객체를 받아서 상위 클래스 생성자로 전달하는 경우도 있다. 이는 특정 예외를 다른 예외로 전환하고 싶을 때 사용한다. 이렇게 하면 전환하기 전의 예외 정보도 담긴다. 이를 예외 체인이라고 한다. 예외 전환에 관해서는 아래의 문단에서 서술한다. 필요에 따라 사용하면 된다.
이렇게 정의된 예외는 원할 때 발생시키면 된다.
1
2
3
4
5
6
public void method(int value) throws OutOfRangeException {
this.value += value;
if(this.value > MAX_VALUE || this.value < MIN_VALUE) {
throw new OutOfRangeException(this.value.toString() + " Out of Range!");
}
}
위와 같이 생성자를 통해 예외를 처리하는 측에 전달하고자 하는 정보를 넘기며 생성하고 throw 하면 된다.
이제 넘겨받은 정보를 예외 처리할때 참조하는 방법을 보자.
1
2
3
4
5
try {
......
} catch(OutOfRangeException e) {
System.out.println(e.getMessage());
}
catch 블록의 매개변수로 받은 예외 클래스의 getMessage() 메소드의 리턴값을 사용하면, 예외 클래스를 던질 때 넘긴 메시지를 참조할 수 있다.
표준 API나 프레임워크에 포함된 예외 클래스들은 이 getMessage()로 받을 수 있는 메시지에 다양한 정보를 포함한다. 따라서 디버깅을 할때에 getMessage()를 사용하면 자세한 정보를 볼 수 있다.
1
2
3
4
5
try {
......
} catch(OutOfRangeException e) {
e.printStackTrace();
}
위와 같이 printStackTrace() 메소드를 사용하면 예외가 발생한 시점의 스택을 추적해서 출력한다. 즉, 예외가 발생한 메소드부터 그 상위 메소드를 차례로 출력한다.
예외 전환 - 언체크 예외
예외 전환은 특정 예외를 다른 예외로 전환하여 던지는 것을 말한다.
예외를 전환하는 이유에는 여러가지가 있지만 먼저 체크 예외를 언체크 예외로 전환하는 경우를 보자.
기본적으로 예외는 발생한 메소드에서 해결할 수 있고, 그것이 더 바람직하다면 해당 메소드가 복구한다. 만약 그렇지 않다면 상위 메소드로 throws하여 호출한 측에 책임을 전가한다.
만약 throws하는 예외가 체크 예외라면 호출하는 측은 try-catch를 쓰거나 throws할 것을 강요당한다. 그렇게 되면 체크 예외를 호출하는 모든 메소드와 그 상위 메소드는 무조건 throws를 써야한다. 예시로 살펴보자.
1
2
3
public void addUser(User user) throws SQLException {
//SQLException이 발생할 수 있는 코드
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public void method1() throws SQLException {
addUser();
......
}
public void method2() throws SQLException {
method1();
......
}
public void method3() throws SQLException {
method2();
......
}
addUser 메소드는 SQLException이 발생할 수 있는 코드를 사용한다.
해당 메소드 내부에서 처리하는 것은 불가능하다고 판단하여 throws로 상위 메소드로 전가했다.
그리고 method1()은 이 addUser 메소드를 코드의 일부에 사용한다. 따라서 마찬가지로 throws를 해야한다. 이는 이 method1()을 호출하는 method2(), method2()를 호출하는 method3()도 마찬가지이다.
method1()은 addUser를 호출하는 부분이 있으니 그렇다 치더라도, method2(), method3() 메소드는 addUser와 같은 SQLException이 발생할만한 부분이 눈에 띄지 않는다.
즉, 개발자가 해당 메소드가 왜 SQLException을 throws 해야 하는지 알기 어렵다는 것이다. 그저 기계적으로 컴파일러가 그렇게 하라 하니까 하는 것 밖에 안된다.
이렇게 계속 전가된 예외는 최상위 메소드를 넘어 시스템으로 넘어가게 된다. 그렇게 되면 단순히 언체크 예외(런타임 예외)가 발생한 것과 별 차이가 없다.
언체크 예외가 발생한 것과 같은 효과를 내기 위해 throws를 모든 메소드 계층에 선언하는 것은 너무 귀찮다. 이를 위해 발생한 체크 예외를 언체크 예외로 전환하여 던질 수 있다.
또한 호출하는 메소드에 따라서 복구를 시도할 수도, 복구를 시도하고 싶지 않거나 할 수 없는 경우가 나뉠 수 있다. 하지만 위와 같이 체크 예외를 던지게 되면 복구를 시도하지 않을 메소드는 계속 무의미한 throws를 해야 한다. 이럴 때 역시 체크 예외를 언체크 예외로 전환하여 던질 수 있다.
1
2
3
public class DuplicatedIdException extends RuntimeException {
public DuplicatedIdException(Throwable cause) { super(cause); }
}
위와 같이 RuntimeException을 상속한 예외는 언체크 예외가 되어 예외처리나 throws를 강요하지 않는다.
또한 예외를 전환할 것이기 때문에 원본 예외의 정보를 보존하기 위해 Throwable을 생성자에서 받는다. 이는 예외 체인을 위한 것이다. 원본 예외를 전달하지 않고 throw 하게 되면 원본 예외의 메시지나 발생 위치의 스택 정보등이 사라지고 새로 throw한 예외의 정보만 남게 된다. 이를 막기 위해 원본의 정보를 Throwable을 통해 받아오는 것이다.
위의 예외 클래스는 ID가 중복되었을 때 발생시킬 예외이다. 예외 전환은 아래와 같이 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
public void addUser(User user) throws DuplicatedIdException {
try {
//SQLException이 발생할 수 있는 코드
} catch(SQLException e) {
if(e.getErrorCode() == /*중복된 ID일때 발생하는 에러코드*/) {
throw new DuplicatedIdException(e);
else {
throw new RuntimeException(e);
}
} finally {
//리소스 정리 등등
}
}
addUser 내에서 SQLException이 발생할 시 catch로 잡은 후, 에러코드를 확인하여 에러의 종류를 확인한다.
만약 ID 중복으로 인한 예외일 경우 DuplicatedIdException을 던진다. 이는 throws를 통해 상위 메소드로 전가된다. 이 예외를 받은 상위 메소드에서도 처리하지 않는다면, 런타임 예외이므로 시스템에서 처리한다.
그 외의 예외일 경우 그냥 RuntimeException으로 포장해서 던진다. RuntimeException은 throws에 명시되지 않았으므로 상위 메소드가 아닌 시스템 측에서 처리하게 된다. 아마 스택 트레이스를 출력하고 비정상 종료하는 등의 처리가 이루어질 것이다.
위의 코드처럼 예외 전환을 사용하게 되면 호출하는 측에 선택권이 생긴다. 아무런 처리도 하지않음으로서 시스템에게 처리를 넘길 수도 있고, 예외를 복구하는 과정을 거치거나, 로그로 남기는 등의 처리를 추가할 수도 있다.
또한, 에러코드를 확인하기 전까지는 모호한 SQLException을 보다 명확환 예외인 DuplicatedIdException으로 전환하여 던졌으므로 상위 메소드에서는 에러코드를 확인할 필요 없이 예외가 던져졌다면 ID가 중복되었음을 바로 판단할 수 있다.
이 개념을 보다 강화하면, 모든 체크 예외를 언체크 예외로 전환하는 방법이 생긴다.
즉 모든 예외는 처리 불가능하다고 단정 짓고 시스템에게 예외 처리를 전가해버리는 것이다. 이후, 복구가 꼭 필요한 부분만 try-catch를 사용하여 처리한다.
이 개념은 하나의 독립된 어플리케이션에서는 적용하기 어렵다. 단 하나의 예외라도 발생하면 비정상 종료되어 버리기 때문이다.
하지만 웹 환경과 같은 곳에서는 수많은 요청과 응답이 오가기 때문에, 런타임 에러로 비정상 종료되어도 특정 요청만 종료된다. 그렇기에 환경에 따라 이러한 방식도 유효하다고 볼 수 있다.